Building an AI-Powered Code Evolution System A Frugal Developer's Journey
AI is fundamentally changing how we write and evaluate code. As a solo developer juggling between different AI coding assistants, I’ve explored everything from OpenAI’s offerings to Claude (my personal favorite) to DeepSeek. Each brings something unique to the table, but there’s a catch that every independent developer knows too well - API costs add up fast.
Why Local AI? A Practical Choice
After watching my OpenAI credits vanish faster than free pizza at a developer meetup (and probably spending enough on API calls to buy several pizzas), I started exploring alternatives. Enter Ollama - an open-source project that lets you run powerful language models locally.
📘 What is Ollama? Ollama is a framework that makes it easy to run large language models locally. It handles model management, provides a simple API, and optimizes performance for your hardware. Learn more about Ollama
The Fun Begins: An AI Experiment
One evening, while manually copying code between ChatGPT and Claude for generation and review, I had a thought: Why not make the AIs talk to each other? The results were… interesting. Sometimes brilliant, sometimes hilariously off-base. It was like watching two rubber ducks debug each other while occasionally speaking in tongues.
Adventures with DeepSeek: A Tale of Two Models
My journey involved experimenting with both DeepSeek-R1 14B and 1.5B variants. The results? Let’s just say it was a choice between accuracy and keeping my MacBook Pro from achieving liftoff.
The 14B Experience: Power Meets Heat
First, I tried DeepSeek-R1 14B:
- Incredibly Accurate: The responses were spot-on
- Superior Understanding: Handled complex code patterns beautifully
- Resource Hungry: My MacBook Pro nearly went up in flames
- Fan Concert: Constant max-speed fan noise became my new workspace ambiance
The 1.5B Compromise: Keeping Cool
After some thermal throttling adventures, I settled on DeepSeek 1.5B for this experiment:
- Good Enough: Still produces solid code most of the time
- Sometimes Bananas: The hallucinations can be entertaining
- Resource Friendly: My MacBook can actually breathe
- Free to Experiment: No API costs and no fire extinguisher needed
The system configuration is straightforward:
const CONFIG = {
MODEL: 'deepseek-r1:1.5b', // Previously used 14b but switched for thermal reasons
DEFAULT_ROUNDS: 5,
MIN_ROUNDS: 2,
MAX_ROUNDS: 6,
PORTS: {
DEFAULT: 5100,
SOLVER: 11434,
REVIEWER: 11435
},
CORS_ORIGINS: ['http://localhost:5173']
};System Architecture: The Complete Picture
Here’s a breakdown of the system’s core components:
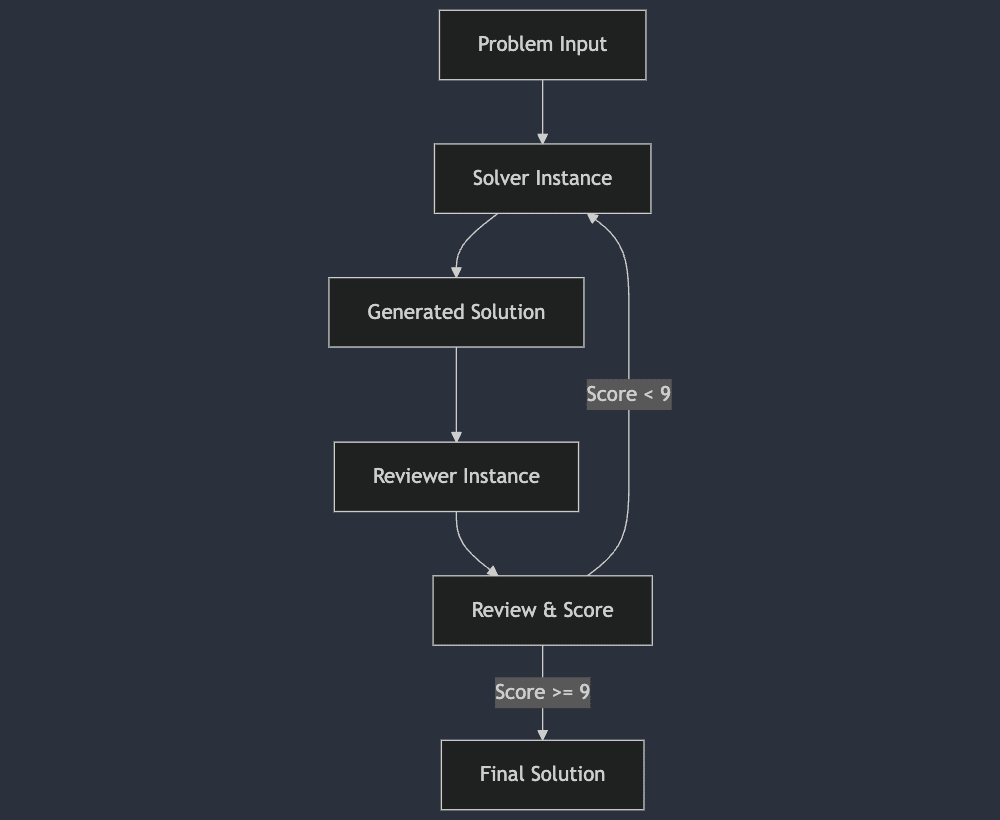
The system is built using Express.js and interacts with two Ollama instances:
- A solver (port 11434) that generates code solutions
- A reviewer (port 11435) that evaluates the code
The Code Generation Process
The solver instance generates solutions using Ollama’s chat API:
async generateSolutionStream(prompt, previousSolution = "", reviewFeedback = "") {
try {
const contextPrompt = previousSolution && reviewFeedback
? `Previous solution:\n\`\`\`javascript\n${previousSolution}\n\`\`\`\n\n${reviewFeedback}\n\nImprove the solution based on the feedback.`
: `Create a JavaScript solution for: ${prompt}\n\nReturn ONLY the code.`;
const response = await fetch(`${this.solverHost}/api/chat`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: CONFIG.MODEL,
messages: [
{
role: "system",
content: "You are a JavaScript expert. Provide only clean, working code without explanations."
},
{
role: "user",
content: contextPrompt,
}
],
stream: true,
})
});
if (!response.ok) {
throw new Error(`Solver API error: ${response.statusText}`);
}
return response;
} catch (error) {
throw new Error(`Solution generation failed: ${error.message}`);
}
}The Review Process
The reviewer evaluates solutions with specific criteria:
async reviewSolutionStream(problem, solution, round) {
try {
const prompt = `Review the following solution for Round ${round}:
**Problem:**
${problem}
**Solution:**
\`\`\`
${solution}
\`\`\`
Provide a detailed review with:
1. What works well
2. What could be improved
3. Score out of 10
Format as:
### Score: [X/10]
### Review:
[Your detailed review]`;
const response = await fetch(`${this.reviewerHost}/api/chat`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: CONFIG.MODEL,
messages: [
{
role: "user",
content: prompt,
}
],
stream: true,
})
});
if (!response.ok) {
throw new Error(`Reviewer API error: ${response.statusText}`);
}
return response;
} catch (error) {
throw new Error(`Review generation failed: ${error.message}`);
}
}Stream Processing Magic
One of the trickier parts was handling the streaming responses from Ollama. Here’s how we manage that:
async processStream(response, writeStream) {
let fullText = "";
let isCodeBlock = false;
let codeContent = "";
const parser = createParser((event) => {
if (event.type === "event") {
try {
const data = JSON.parse(event.data);
if (data.message?.content) {
const content = data.message.content;
// For code blocks, ensure proper formatting
if (content.includes("```")) {
isCodeBlock = !isCodeBlock;
if (!isCodeBlock && codeContent) {
const cleanCode = this.cleanCodeBlock(codeContent);
fullText += cleanCode;
writeStream(cleanCode);
codeContent = "";
}
} else if (isCodeBlock) {
codeContent += content;
} else {
fullText += content;
writeStream(content);
}
}
} catch (error) {
console.error("Error parsing stream chunk:", error);
}
}
});
try {
for await (const chunk of response.body) {
const text = new TextDecoder().decode(chunk);
parser.feed(text);
}
} catch (error) {
console.error("Error processing stream:", error);
throw error;
}
return fullText;
}Real-World Challenges (aka The Fun Part)
1. Resource Management
Running DeepSeek locally on an M1 MacBook Pro taught me some valuable lessons about hardware limits:
- Memory Usage: The 14B model needed about 8GB per instance, while 1.5B runs comfortably with 2-3GB
- Thermal Management: With the 14B model, my MacBook went into jet engine mode. The 1.5B version keeps things much cooler
- Disk Space: The 14B model needs about 8GB of disk space, while 1.5B only needs about 2GB
- Performance vs Temperature: Found that accuracy improvements from the 14B model often weren’t worth the thermal throttling
2. Connection Management
The system includes robust connection checking:
async checkConnection() {
try {
const [solverTags, reviewerTags] = await Promise.all([
fetch(`${this.solverHost}/api/tags`),
fetch(`${this.reviewerHost}/api/tags`)
]);
if (!solverTags.ok || !reviewerTags.ok) {
return false;
}
const [solverData, reviewerData] = await Promise.all([
solverTags.json(),
reviewerTags.json()
]);
const solverHasModel = solverData.models?.some(
(model) => model.name === CONFIG.MODEL
);
const reviewerHasModel = reviewerData.models?.some(
(model) => model.name === CONFIG.MODEL
);
if (!solverHasModel || !reviewerHasModel) {
console.warn(`Model ${CONFIG.MODEL} not found. Please run: ollama pull ${CONFIG.MODEL}`);
return false;
}
return true;
} catch (error) {
console.error("Connection check failed:", error);
return false;
}
}Setting Up Your Own Instance
Want to join the fun? Here’s how to get started:
-
Install Ollama:
curl -fsSL https://ollama.com/install.sh | sh -
Pull the DeepSeek model:
ollama pull deepseek-r1:1.5b -
Start two Ollama instances:
# Terminal 1 ollama serve # Terminal 2 OLLAMA_HOST=127.0.0.1:11435 ollama serve -
Clone and run the project:
git clone https://github.com/mrSamDev/ai-code-evolution cd ai-code-evolution && cd server npm install node x
What I’ve Learned
This experiment has been great for:
- Solo Projects: When you need a second pair of eyes (even if they’re occasionally cross-eyed)
- Learning: Both about AI and how creative its mistakes can be
- Code Review: When it works, it’s impressive. When it doesn’t, it’s entertaining
- Cost Savings: My wallet is happier, even if my CPU isn’t
Join the Adventure
Got your own AI coding stories? Watched your local model go completely off the rails? Let’s share our experiences - both the successes and the hilarious failures. After all, who doesn’t love a good “AI went bananas” story?
The complete code is available on GitHub
Updates and Discussion
This has been a fun experiment in pushing the boundaries of what’s possible with local AI models. Sometimes it works brilliantly, sometimes it hallucinates wildly, but it’s always interesting. Have you tried running AI models locally? What chaos have you witnessed? Let’s discuss in the comments below!